What is vector search
The traditional lexical search works very well with structured data but what happens when we are dealing with unstructured data like images, video, raw text, etc? Vector search tries to address the limitations of the lexical search by providing the ability to query unstructured data. While the lexical search tries to match the literals of the words or their variants, vector search attempts to search based on the proximity of the data and query points in a multi-dimensional vector space. Semantic search uses vector search to achieve its ultimate goal - to focus on the intent or the meaning of data.
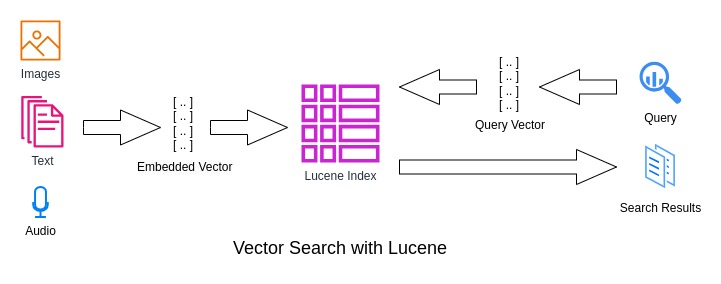
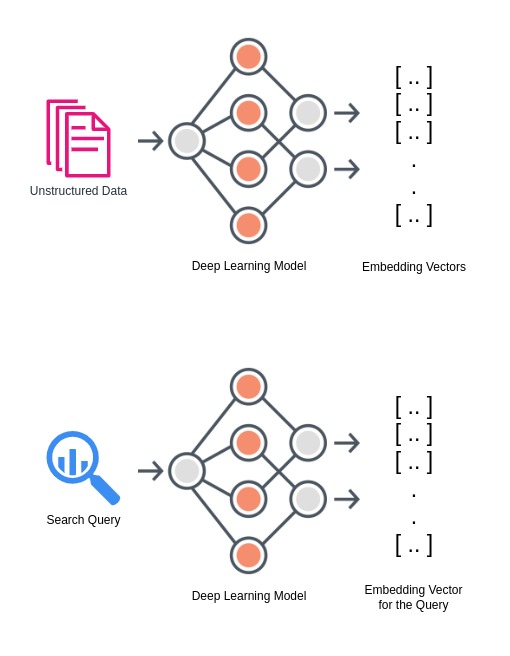
Semantic search is achieved with deep learning and vector search. With deep learning models, the unstructured data can be represented as a sequence of floating point values known as embedding vectors. These vector representations are then indexed (using Lucene API for example). Embedding vectors that are close to one another represent semantically similar pieces of data.
Vector search finds similar data using approximate nearest neighbor (ANN) algorithms. One such algorithm is the Hierarchical Navigable Small World Graphs (HNSW) and Lucene has its implementation for this algorithm. Embedding vectors for queries that are produced using the same deep learning models are then used to identify semantically similar pieces of data. Several corporations have started to leverage semantic search in solving interesting challenges and use cases like Spotify enabling users to find more relevant content using semantic search etc.
A Hands-on with Vector Search and Lucene
For this hands-on example, we have leveraged OpenAI’s Wikipedia embeddings dataset (25k documents). This dataset includes an embedded vector representation of the title and content fields. The embedding vector for the query has been generated using OpenAI’s embeddings endpoint. The vector fields in the dataset and embedding vector for the query have 1536 dimensions. There are mainly three sections of the code: Setup, Indexing of data, and Querying.
Index Setup
We need a place to keep the index files and for that, we used ByteBuffersDirectory to conveniently keep the index files in the heap memory. Alternatively, if we want to store the index files in the file system we can use FSDirectory.
Directory index = new ByteBuffersDirectory();
Addressing Lucene’s limitation of a maximum of 1024 dimensions for vector fields
While many models are less than 1024 dimensions we are using an OpenAI based model which is of 1536 dimensions. Lucene by default has a limitation of a maximum of 1024 dimensions for vector fields and there have been discussions in the Lucene community on increasing this limit. Since our dataset and embedding vector for the query is of 1536 dimensions we had to create a workaround to make this work. Our workaround involved setting a Lucene95Codec codec with an overridden getKnnVectorsFormatForField method to enable indexing of vectors with 1536 dimensions using HighDimensionKnnVectorsFormat.
Lucene95Codec knnVectorsCodec = new Lucene95Codec(Mode.BEST_SPEED) {
@Override
public KnnVectorsFormat getKnnVectorsFormatForField(String field) {
int maxConn = 16;
int beamWidth = 100;
KnnVectorsFormat knnFormat = new Lucene95HnswVectorsFormat(maxConn, beamWidth);
return new HighDimensionKnnVectorsFormat(knnFormat, 1536);
}
};
IndexWriterConfig config = new IndexWriterConfig(new StandardAnalyzer()).setCodec(knnVectorsCodec);
private static class HighDimensionKnnVectorsFormat extends KnnVectorsFormat {
private final KnnVectorsFormat knnFormat;
private final int maxDimensions;
public HighDimensionKnnVectorsFormat(KnnVectorsFormat knnFormat, int maxDimensions) {
super(knnFormat.getName());
this.knnFormat = knnFormat;
this.maxDimensions = maxDimensions;
}
@Override
public KnnVectorsWriter fieldsWriter(SegmentWriteState state) throws IOException {
return knnFormat.fieldsWriter(state);
}
@Override
public KnnVectorsReader fieldsReader(SegmentReadState state) throws IOException {
return knnFormat.fieldsReader(state);
}
@Override
public int getMaxDimensions(String fieldName) {
return maxDimensions;
}
}
Indexing data
All we do here is go through the documents in the dataset archive and add the documents to the index using an instance of the IndexWriter. KnnFloatVectorField is used to index title_vector and content_vector fields with cosine as a similarity function. These fields are the embedded vector representation of the actual title and content fields.
try (ZipFile zip = new ZipFile("vector_database_wikipedia_articles_embedded.zip");
IndexWriter writer = new IndexWriter(index, config)) {
CSVReader reader = new CSVReader(new InputStreamReader(zip.getInputStream(zip.entries().nextElement())));
String[] line;
int count = 0;
while ((line = reader.readNext()) != null) {
if ((count++) == 0) continue; // skip the first line of the file, it is a header
Document doc = new Document();
doc.add(new StringField("id", line[0], Field.Store.YES));
doc.add(new StringField("url", line[1], Field.Store.YES));
doc.add(new StringField("title", line[2], Field.Store.YES));
doc.add(new TextField("text", line[3], Field.Store.YES));
float[] titleVector = ArrayUtils.toPrimitive(Arrays.stream(line[4].replace("[", "").replace("]", "").
split(", ")).map(Float::valueOf).toArray(Float[]::new));
doc.add(new KnnFloatVectorField("title_vector", titleVector, VectorSimilarityFunction.COSINE));
float[] contentVector = ArrayUtils.toPrimitive(Arrays.stream(line[5].replace("[", "").replace("]", "").
split(", ")).map(Float::valueOf).toArray(Float[]::new));
doc.add(new KnnFloatVectorField("content_vector", contentVector, VectorSimilarityFunction.COSINE));
doc.add(new StringField("vector_id", line[6], Field.Store.YES));
if (count % 1000 == 0) System.out.println(count + " docs indexed ...");
writer.addDocument(doc);
}
writer.commit();
} catch (Exception e) {
e.printStackTrace();
}
Query
Finally, we query the Lucene index. The query is Is the Atlantic the biggest ocean in the world?. We’ve borrowed the step mentioned in OpenAI’s cookbook to encode this query with OpenAI’s embedding model to generate the embedding vector for the query. The embedding vector for the query is stored in the query.txt file is then used to query the content_vector field of the index by passing an instance of the KnnFloatVectorQuery to the IndexSearcher’s search method.
IndexReader reader = DirectoryReader.open(index);
IndexSearcher searcher = new IndexSearcher(reader);
for (String line: FileUtils.readFileToString(new File("query.txt"), "UTF-8").split("\n")) {
float queryVector[] = ArrayUtils.toPrimitive(Arrays.stream(line.replace("[", "").replace("]", "").
split(", ")).map(Float::valueOf).toArray(Float[]::new));
Query query = new KnnFloatVectorQuery("content_vector", queryVector, 1);
TopDocs topDocs = searcher.search(query, 100);
ScoreDoc[] hits = topDocs.scoreDocs;
System.out.println("Found " + hits.length + " hits.");
for (ScoreDoc hit: hits) {
Document d = searcher.storedFields().document(hit.doc);
System.out.println(d.get("title"));
System.out.println(d.get("text"));
System.out.println("Score: " + hit.score);
System.out.println("-----");
}
}
Output
Below is what the output looks like.
Starting indexing of data ...
1000 docs indexed ...
.
.
.
25000 docs indexed ...
Running queries ...
Found 1 hits.
Atlantic Ocean
The Atlantic Ocean is the world's second largest ocean. It covers a total area of about . It covers about 20 percent of the Earth's surface. It is named after the god Atlas from Greek mythology.
.
.
.
NOAA In-situ Ocean Data Viewer Plot and download ocean observations
www.cartage.org.lb
www.mnsu.edu
Score: 0.9364375
-----
Try it out yourself!
For your convenience, we have put an end-to-end working example of the above out on GitHub for you to explore and play with. We’d love to hear from you!
What’s next?
As a part of this series of blog posts, some of the next posts will cover our work in speeding up vector search in Lucene with GPUs.